
Storage Engines
The storage engine (or database engine) is a software component of a database man‐ agement system responsible for storing, retrieving, and managing data in memory and on disk, designed to capture a persistent, long-term memory of each node.
Storage engines such as BerkeleyDB, LevelDB and its descendant RocksDB, LMDB and its descendant libmdbx, Sophia, HaloDB,
Row-Oriented Data Layout
Row-oriented database management systems store data in records or rows. Their layout is quite close to the tabular data representation, where every row has the same set of fields.
row-oriented stores are most useful in scenarios when we have to access data by row, storing entire rows together
Because data on a persistent medium such as a disk is typically accessed block-wise a single block will contain data for all columns. This is great for cases when we’d like to access an entire user record, but makes queries accessing individual fields of multiple user records
Column-Oriented Data Layout
Column-oriented database management systems partition data vertically.Here, values for the same column are stored contiguously on disk
Column-oriented stores are a good fit for analytical workloads that compute aggregates, such as finding trends, computing average values, etc. Processing complex aggregates can be used in cases when logical records have multiple field
Assume the table have id ,data and price which will be stored as below so if you want to calculate the total price it will be single disk read IO.
Symbol: 1:DOW; 2:DOW; 3:S&P; 4:S&P
Date:1:08 Aug 2018; 2:09 Aug 2018; 3:08 Aug 2018; 4:09 Aug 2018
Price: 1:24,314.65; 2:24,136.16; 3:2,414.45; 4:2,232.32
Indexing
An index is a structure that organizes data records on disk in a way that facilitates efficient retrieval operations.
There are 2 index type
- Primary index : index created by the database itself using primary key
- Secondary indexes : Created by the user based on need
Secondary indexes
Mostly Secondary indexes will hold the primary key index reference and primary index will hold the address for the data in memory the advantage of using this method is if update/delete is easy because updating primary index location is fine but it need 2 lookup when we searching.
The way the index stored is classified in 2 types
- clustered index : Where the physical order of the rows in the table corresponds to the order of the index’s keys. let assume you have username filed as primary index then the data stored in data file be sorted based on username.
- non clustered index: does not maintain the order of primary index
Hard Disk Drives
On spinning disks, seeks increase costs of random reads because they require disk rotation and mechanical head movements to position the read/write head to the desired location. However, once the expensive part is done, reading or writing contiguous bytes (i.e., sequential operations) is relatively cheap.
The smallest transfer unit of a spinning drive is a sector, so when some operation is performed, at least an entire sector can be read or written. Sector sizes typically range from 512 bytes to 4 Kb
Solid State Drives
SSD is built of memory cells, connected into strings (typically 32 to 64 cells per string), strings are combined into arrays,arrays are combined into pages, and pages are combined into blocks .Blocks typically contain 64 to 512 pages.
The smallest unit that can be written or read is a page.
B-Tree vs B+ Tree
B-Trees allow storing values on any level: in root, internal, and leaf nodes.
B+ Trees store values only in leaf nodes all operations (inserting,updating, removing, and retrieving data records) affect only leaf nodes and propagate to higher levels only during splits and merges.
LSM tree
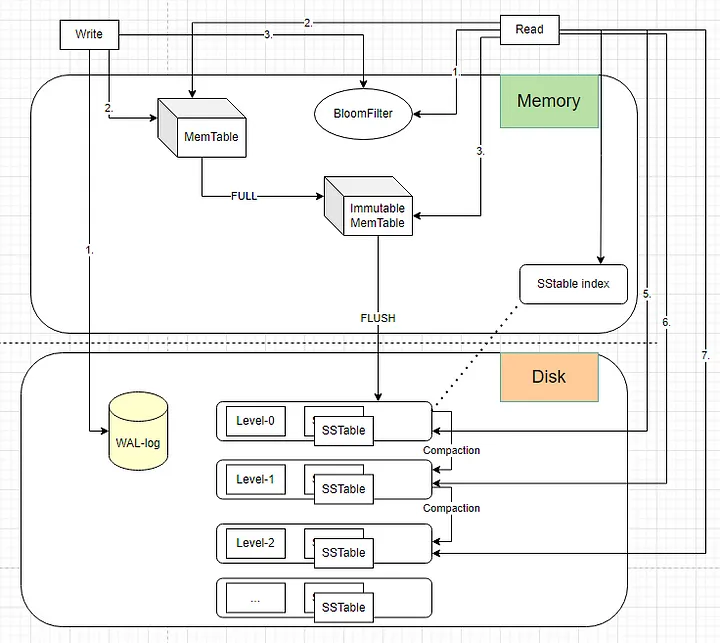
Write
- First it writes in WAL log and appended to an in-memory component known as the memtable.when Mem-table became full, an Immutable MemTable was created, and a new Mem-table became empty.
- When Immutable Memtable is full, a FLUSH happens, dumping the “balanced tree in RAM” into a disk, called SSTable. which contains sorted values plus an index.
- SSTables are immutable, meaning once written, they are not modified. Any updates or deletes are handled by writing new SSTables with the modified data.Compaction is the process of merging and removing obsolete SSTables to reduce storage space and improve read performance.
Bloom Filters
- LSM trees often use Bloom filters to quickly check whether a key is present in the SSTables. Bloom filters are space-efficient data structures that provide a probabilistic answer to membership queries.
OLTP (Online Transaction Processing) Databases
- OLTP databases are designed for handling transactional workloads, which involve a high volume of short, simple transactions.
- These transactions typically involve frequent insert, update, and delete operations on individual records or small sets of records.
- OLTP databases prioritize fast response times, concurrency, and data integrity, making them suitable for applications such as e-commerce, banking, and order processing systems.
- Examples of OLTP databases include MySQL, PostgreSQL, Oracle Database, and Microsoft SQL Server.
OLAP (Online Analytical Processing) Databases
- OLAP databases are optimized for performing complex queries and analysis on large volumes of historical data.
- These databases are designed to support decision-making processes by providing capabilities for data aggregation, slicing, dicing, and drilling down into data to uncover insights and trends.
- OLAP databases typically store data in a denormalized format, optimizing them for analytical queries rather than transactional operations.
- OLAP databases are commonly used in business intelligence (BI), data warehousing, and reporting applications.
- Examples of OLAP databases include Amazon Redshift, Google BigQuery, Snowflake, Apache Hive, and Apache Spark.
Resources
- Discover and learn about 960 database management systems
- Knowledge Base of Relational and NoSQL Database Management Systems
Indepth
-
https://medium.com/@hnasr/following-a-database-read-to-the-metal-a187541333c2
-
https://medium.com/@hnasr/database-pages-a-deep-dive-38cdb2c79eb5
To overcoming the CAP theorem in building data systems. It proposes a solution that involves using immutable data, rejecting incremental updates, and recomputing queries from scratch each time. This approach eliminates the complexities associated with eventual consistency.
The key properties of the proposed system include: 1. Easy storage and scaling of an immutable, constantly growing dataset. 2. Primary write operation involving adding new immutable facts of data. 3. Recomputation of queries from raw data, avoiding the CAP theorem complexities. 4. Use of incremental algorithms to lower query latency to an acceptable level.
The workflow involves storing data in flat files on HDFS, adding new data by appending files, and precomputing queries using MapReduce. The results are indexed for quick access by applications using databases like ElephantDB and Voldemort, which specialize in exporting key/value data from Hadoop for fast querying. These databases support batch writes and random reads, avoiding the complexities associated with random writes, leading to simplicity and robustness.
Global secondar index Used in distributed shared database where the indexing is in global so when ever request go to the DB proxy that is infront of sharded DB it will do the query on GSI to get the doc shard database ref such that we don’t want to query on all shard.**
Resources
- https://medium.com/@hnasr/following-a-database-read-to-the-metal-a187541333c2
- Build your own Database Index: part 1
- Database Fundamentals
- https://www.geeknarrator.com/blog/social-posts/ten-things-about-your-database
- Advanced Database Systems 2024
- https://planetscale.com/blog/btrees-and-database-indexes
SQL
CLient → Query enging (thread/process per client) → storage/engine (io/treads) → Disk
they have thread and locks and shared memory for communication
Cassandra client → MainThread pool(threads per client) →MMapedFile (kernel task) - > Storage
Locks moved to kernel